Update 1: Added Exchange & Virtualization + NFS Support statement. Split of DAG failover / 20 sec timeout tips.
Update 2: At 1.4. blogger completely destroyed my article as a April-Joke, so I had to rearrange the text again. I added some small updates to the text based on your feedback. Thanks for sending me change ideas.
Update 3: 11.April 2014 Added some planning informations round about CPU/RAM/DISK to section 2. and 3.
Update 4: 24. April 2014 Added Exchange Update Link with Exchange 2013 CU3 example.
Update 5: 23. June 2014 Added Transport Role and CAS role specific backup informations. (See chappter 5. and 6.)
Update 6: 31. July 2014 Added recommended Hotfixes to DAG recommendations section.
Update 7: 01. August 2014 Added a tip from a forum member regarding Public Folder databases and VSS timeouts.
Update 8: 06. November 2014 Added Tip “x)” that addresses VSS Timeouts.
Update 9: 27. November 2014 Corrected a statement at the CAS HA section.
Update 10: 18.05.2015 Added the IP Less DAG section.
Update 11: 20.09.2015 Added Tip y) and z) regarding existing SnapShots
Update 12: 27.01.2016 Added new VMware Exchange on vSphere guide and updated h) because of actual SnapShot changes in vSphere6 actual Patch level. As well I placed h) more prominent on the beginning of the chappter.
Update 13: 04.03.2016 Changed tips f), i) j) k) l) v) y); Changed Priority for Tips; Changed SnapShot background story; Added tips: aa), ab)
Update 14: 29.03.2016 Update the “3. VMware+Exchange Design + Background informations:” section with more tips.
Update 15: 20.04.2016 Added Restore Tips and tricks ac)-am)
Update 16: 29.06.2016 Added chappter “7.” with “Storage Spaces are not supported within a VM”.
Update 17: 31.08.2015 Added new NFS discussions and statements from the internet. Added tip an)
Update 18: 28.02.2017 Changed the NFS statement slightly to reflect my latest discussions with other Exchange experts. + Minor updates on the other topics make them better understandable. Thanks for the feedback here.
Update 19 12.10.2017 Updated most part of the text and links. Added tip “ao)” regarding vRDMs.
Update 20 02.11.2017 Tip j) was corrected. There is no reg key to influence snapshot commit parallel disk processing within same VM.
Update 15.06.2018 Tip ap) Not all Logfiles are deleted at Logfile Truncation in a DAG?
Update 24.09.2018 Tip aq) WMI Error 0x80041032 after Windows Updates or Host Update.
Update 26.10.2018 Added 9. Full Mailbox restore examples section
Update 04.02.2019 Added chappter “10. Additional Planning for Windows 2019”
Update 28.07.2020 Added Details for physical server backup with Veeam Agent for Windows
Update 14.09.2020 Added Tip ar) for Kerberos only authentication scenarios.
Here you can find my updated general recommendations for Exchange/Exchange DAG on VMware together with Veeam Backup & Replication.
1. Check Microsoft Exchange 2013 Virtualization Topic:
http://technet.microsoft.com/en-us/library/jj619301.aspx
– Exchange 2013 DAG are supported on virtualization platforms.
– Microsoft say: Snapshots are not supported, because they are not application aware and can have unintended and unexpected consequences.
Because Microsoft do not support Snapshots at Exchange, you need to contact your backup or virtualization vendor for any snapshot related questions/support requests. The question is why should someone then use Snapshots (for backups) with Exchange when Microsoft do not support it? Why not use agent based backup methods? The data amount is critical. When you do Agent based backups you need to process full backups regularly. With VMware based or similar backup methods you can use Incremental Forever backup methods to minimize the backup window. Another really game changer is the restore part. With an Agent you have to transport back your TBs of data and with Image level backup methods you can restore an Exchange service with Instant VM Recovery in some minutes (usually 2-3min + boot time). Next argument is that Agents usually depends on the Exchange Version and Update. If Microsoft creates a new security patch/update and you have to wait until your Agent vendor support this, you run into potentially security issues. With Veeams Agentless backup method, it will automatically process exchange backups without a change as the VSS framework will not change for consistency. The Exchange Restore part with Veeam Explorer for Exchange will automatically load the ese.dll from the backed up exchange server and can access the data usually without an update as it uses the standard ese.dll to access the data. And last thing Veeams agentless backup is affordable compared with many other agent based Exchange backup solutions.
However if you use Virtualization based backups (VMware/Hyper-V) you need snapshots for backup. In case of Veeam by enabling Veeam Guest Processing, Veeam uses VSS to bring Exchange in an Application aware backup/restore state before snapshot are started. You can check this by Windows Event Log. There you can find Messages that say “Exchange VSS Writer <instance GUID> has processed pre-restore events successfully.” and “Exchange VSS Writer (instance GUID) has processed post-restore events successfully.”. The Event IDs are around number 96xx. They are different in each Exchange Version, so search for the text to check if your Backup application use VSS on a Microsoft recommended way.
Link to the Microsoft compatibility list for VMware: https://www.windowsservercatalog.com/results.aspx?&bCatID=1521&cpID=11779&avc=0&ava=0&avq=0&OR=1&PGS=25&ready=0
Another request that I hear frequently is that the backup vendor needs to be “certified” for Exchange backups. Over the years I did not find any kind of certification program from Microsoft for Exchange. A backup vendor can only certify the platform (Windows) and usually all backup vendors have those.
2. VMware NFS based Datastores and Exchange?
Back in the old times Microsoft had created a KB entry that stated that NFS storage is not supported. Now you will say NFS and Windows? NFS is used in many cases as main storage for VMware and the VM hard disks are written as vmdk files to it.
Originally the statement was created at a time when some non matured NFS storage had some reliability issues under VMware.
Over time Microsoft kept this NFS non supported statement in their documentation:
https://technet.microsoft.com/en-us/library/jj619301(v=exchg.160).aspx
“All storage used by an Exchange guest machine for storage of Exchange data must be block-level storage because Exchange 2016 doesn’t support the use of network attached storage (NAS) volumes, other than in the SMB 3.0 scenario outlined later in this topic. Also, NAS storage that’s presented to the guest as block-level storage via the hypervisor isn’t supported.”
There is a deep discussion going on in the industry why this is case technically. As a lot of customers run their Exchange systems on NFS based VMware Datastores without a problem in the last years, the question is if the statement is still there for technical reasons.
At least from my field experience as backup architect I can say that there is a specific thing to look for when it comes to reliable VMware Backups when Exchange run on NFS. VM Snapshot commit processes on NFS datastores can lead into higher VM stun times and DAG failovers are more likely. Please check below the tips arround HotAdd processing and Latency optmizations. It looks like that specifically Hyperconverged Systems tend to run into issues there and the vendor blame the backup vendors to fix. You can easily do a test to sort this out, by creating just VMware Snapshots manually and release it later. Follow all the recommendations below and create a manual VMware Snapshot at the production exchange (load) and release it after 15 min. There should not be any fail over in the DAG cluster.
If you want to dig deeper into the NFS unsupported discussion you can read the following:
http://windowsitpro.com/blog/nfs-and-exchange-not-good-combination
Please check out this article, it describe the main idea why NFS Datastores for Exchange loads are not an good idea. (Teasers: Exchange Error -1018 (JET_errReadVerifyFailure); NFS can abort transactions only on a best effort base and can cause corruptions in the database.)
However Microsoft added neccessary functionallity to SMB3.0, so in case you run Exchange on Hyper-V Win2012/2012R2 you can use SMB3.0 shared storage on Windows File Server 2012/2012R2. You have to place Exchange data into VHD/VHDX then.
There is lately a discussion that VMware virtualized SCSI driver will abstract the abort transaction and answers to the request virtually.
Check out Eric_W comments on the following website: https://social.technet.microsoft.com/Forums/en-US/c8b4a605-3083-4d0f-b3aa-62ea57cc6d43/support-for-exchange-databases-running-within-vmdks-on-nfs-datastores?forum=exchangesvrgeneral
He describes why this is not a final answer for NFS Storage under VMware and Exchange Databases. Exchange send abort commands to the storage and block storage follow those commands. Within NFS this command can ignore the command. So the discussed solution is that the VMware virtual SCSI driver emulate the abort command and tell the application that it was aborted. But the stage on the NFS disk side is potentially not reflecting this (corruption). As Exchange recovery process relay on the physical correct data this is problematic and the corruption detection process will report a Jet Error 1018. If you already ran into this error, check the following: http://www.exchangerecover.com/blog/exchange-server-error-messages.html
3. VMware+Exchange Design + Background informations:
http://www.vmware.com/files/pdf/vmware-microsoft-exchange-server-2016-on-vsphere-best-practices-guide.pdf
http://www.vmware.com/de/business-critical-apps/exchange/microsoft-support.html
Please check there the links and the whitepapers on the bottom of the page. The whitepapers containing outstanding background information for your exchange platform design.
There are also 2 interessting Webinars from VMware
http://vee.am/bpexchangeVMware
http://vee.am/bpexchangeHyperV
Universal Tips for VMware and Hyper-V
– Do not go higher than 2-to-1 in virtual CPU to physical CPU Core ratio. Microsoft strongly recommend a ratio of 1-to-1 on the host where the Exchange Server runs.
– Do not use Hyper-Threading at the Exchange sizing. Calculate with the physical cores.
– Exchange is not NUMA aware. So if you can, please size the Exchange VM in a way, that it can run within a single NUMA node. The idea is to not give Exchange more resources just because they are free and available. Let the Exchange Server run in a single NUMA node if the resources are enough for your size. This would allow Exchange to work with the direct memory access.
– Use thick provisioning for the disks for better performance but use thin provisioning for backup and restore optimization. Now you have to choose :-)
– Give the OS disk enough spare space and place it on a fast storage system as well (do not place it on a datastore with hundreds of other VM boot volumes.). This is a very critical an important step.
– Do not enable deduplication (not supported by Microsoft) or compression (not recommended by Microsoft) on your primary storage that runs the virtualized Exchange workload.
– Use virtualization infrasturcture anti-affinity rules to avoid that members of the same DAG run on the same virtualization host.
– Place DAG members on different storages to avoid issues when a whole storage system is not accessible.
– Exchange Server usually uses a lot of memory. Don´t forget to plan enough disk space for the Pagefiles. I saw so many disk designs that have forgotten that part.
For Hyper-V:
– Do not use Dynamic Memory
– Reserve 2 physical Cores for the Host OS
– If you perform on Veeam Host Backups don´t forget to add or plan the needed resources for this on the host (RAM/CPU)
– Use VHDX whenever it is possible as it has up to 64TB volumes, improved sector alignment and more corruption resistance on power failures.
– Don´t forget to plan the space for the *.bin file (equal to memory size)
Check if you have the latest Exchange Updates installed. For Example:
Cumulative Update 3 for Exchange Server 2013
to address random backup problem with Event ID 2112 and 2180
Exchange Calculator:
http://blogs.technet.com/b/exchange/archive/2015/10/15/exchange-server-role-requirements-calculator-update.aspx
4. More Veeam specific Exchange Tips and Tricks for DAG and mailbox role backups:
In general, if you use virtualization based backups for Exchange, there is a chance to hit one of 2 problems:
– Exchange DAG cluster failovers
– Exchange VSS timeouts (Exchange hard coded 20 second timeout between start of consistency processing and release of it).
If you design your Exchange environment in the below described way you will likely prevent those problems and you address the needed technical requirements/settings for optmized VMware DRS, Storage DRS and vMotion automatically.
Below the list of tips, you can find some insights regarding restore.
Exchange DAG uses a network based heartbeat between the DAG members. When VMware Snapshots are committed, the delta changes are written back to the original storage space. Over time VMware enhanced the process starting from a “Hold on and write a data chunks back and release the VM … repeat” to a process that is similar to Storage vMotion. It was finally implemented with the ESXi 6 U1 Februar 2016 patch levels. It depends as well on the sizes of the disks. If you want to read more about it, you can use the following 2 resources:
http://www.virtualtothecore.com/en/vsphere-6-snapshot-consolidation-issues-thing-past/
https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=1015180
An aggressive DAG Cluster heartbeat (default settings) can detect one or more of that VM holds/stuns as a network outtake and may lead into a DAG cluster failover. Typically vMotion, Storage vMotion or manual SnapShot releases lead then into the same issue.
These failovers are likely transparent to the Exchange users but can cause 2 problematic situations:
- Multiple cluster failover/failbacks can bring extra load (100% CPU usage) to the Exchange background services (e.g. indexer) and can cause Client/Outlook timeouts and connection drops.
- When Failover is performed during backup the backup software is not able to truncate the logs as active/passive databases are changed within the backup process. Likely you will see error [VSS_WS_FAILED_AT_BACKUP_COMPLETE]. Error code: [0x800423f3] then. But keep in mind that this error can be caused from other things as well (see below)
For DAG clusters there are 2 ways in case of Job design:
– Repository: Per Job chain with all DAG members in same job.
– One DAG member per Job
The idea of the first one is to use Veeam Inline Deduplication to reduce data amount significant (as the DAG memebers have a lot of replicated data). But in case you run into Snapshot commit issues with Cluster failovers, this can be negative as it is likely that shortly after a cluster failover the next snapshot commit happens on the other member. The result would be double cluster failover within short time. In theory this should not be a problem, but I saw customers struggling with it because the index service consume then 100% of the CPU for a long time and User connections timed out. If you want to be 100% on save side or use per VM chain Repository setting anyway, create one Job per DAG member (or site) and schedule the Jobs at different times within the night.
Veeam Exchange DAG processing at Veeam Backup & Replication managed Veeam Agent for Windows:
– Creates a transactionally consistent backup of Microsoft Exchange databases. In the case of DAG, only passive database copies are VSS processed; active ones are excluded from VSS freeze operations when passive copies are within the same Veeam Job covered. If during backup, the active status changes to a VM that still needs to be backed up, then we process consistency there if there was no other passive DB VSS processing (rare case).
– Independently from consistency status, all database EDB files from all servers will be backed up. You can enable Veeam per Job chains to use deduplication across VMs from this Job.
– During any backup of Exchange with Classic DAG or “IP less”, “DAG” or “standalone”, we notify Exchange writers about the successful backup. The writer itself decides if it will truncate logs for specific Exchange databases. We do not send truncation command directly to Exchange services, the writer itself decide. Based on the internal design of Exchange, all log truncations will be replicated to all database copies of a specific database (even from passive to active). For example, Veeam can not influence that a truncation that happened on the passive DB will not be replicated to the active DB. However, you can disable all log truncations by “Copy only” processing within the Veeam Job Guest processing options.
– Veeam offers to add the full exchange DAG cluster by adding servers as “Failover Cluster”. This option helps to select all servers automatically. It will not influence any of the above-documented processing for consistency, which DBs are backed up, and if log truncation happens or not. For IP-less DAGs, this option is not available, and you have to add all DAG members to the same Veeam Job manually.
More details within the Microsoft documentation (works the same way in later Exchange versions): https://docs.microsoft.com/en-us/exchange/client-developer/backup-restore/exchange-writer-in-exchange-2013?redirectedfrom=MSDN
======
To address all the above described things, check out the following tips and tricks:
Tips for preventing Exchange DAG cluster failovers:
Cause:
In general you need to prevent big snapshot files. This can be achieved by:
- reducing disk block changes at backup time window (reduce workload)
- keeping the snapshot lifetime as small as possible, because less lifetime means less changes in the snapshot file and finally less problems at snapshot commit when this data need to be written into the original vmdk file.
Tips:
a)
Increase the DAG heartbeat time to avoid cluster fail over (no reboot or service restart needed, they are online after you press enter).
On a command line (with admin rights)
cluster /prop SameSubnetThreshold=20:DWORD
cluster /prop SameSubnetDelay=2000:DWORD
cluster /prop CrossSubnetThreshold=20:DWORD
cluster /prop CrossSubnetDelay=4000:DWORD
cluster /prop RouteHistoryLength=40:DWORD
RouteHistoryLength need to be double the amount of CrossSubnetTrashhold.
You can check the settings with:
cluster /prop
After changing those settings, perform an manual Snapshot at VMware Client and release it after 3 seconds. If a DAG failover is performed, please check tips below and work with VMware Support till this process works without exchange failover. After that you can work on the Veeam side by optimizing backup infrastructure.
an)
If you face [VSS_WS_FAILED_AT_BACKUP_COMPLETE]. Error code: [0x800423f3] and tip a) didn´t helped, check for dismounted databases and mount or delete them.
ao)
Do not use vRDM. Sometimes architect think that the last bit of performance enhancement is really needed but forget that there are several downsides of that decisions. Specifically if the VM run in Snapshot mode all writes will go to snapshot files that are usually placed next to the vmx file. You can change the folder by changing the work dir to another storage area, but overall all disks will have the snapshot file in the same folder on same storage. You will see a write performance reduction during backup (or during manual created snapshots) and snapshot commit is hell when fast IOs are neeed with low latency. => Use vmdks as the snapshot files are placed in the same storage area. If you really think that this performance difference is huge (beside that VMware had shown it is not the case 8 years ago) add 1-2 more spindles or a SSD to cover that performance gap. Your system would work much more stable and you get all the typical VMware benefits.
b)
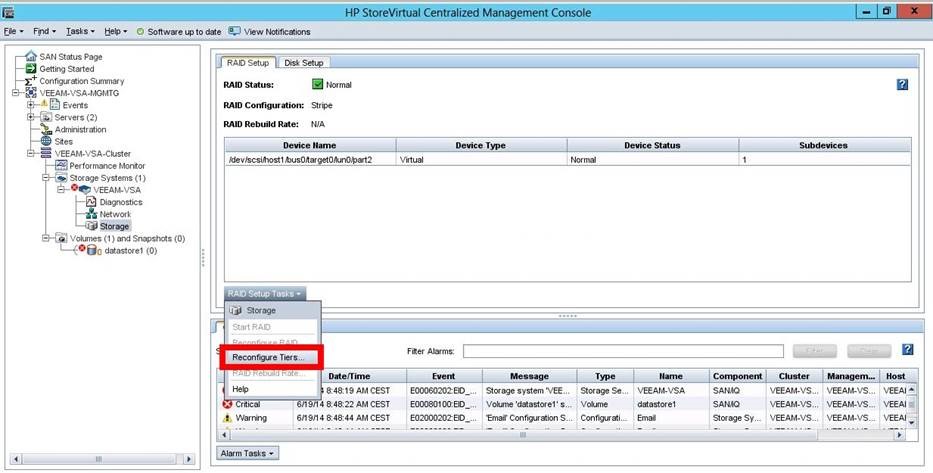
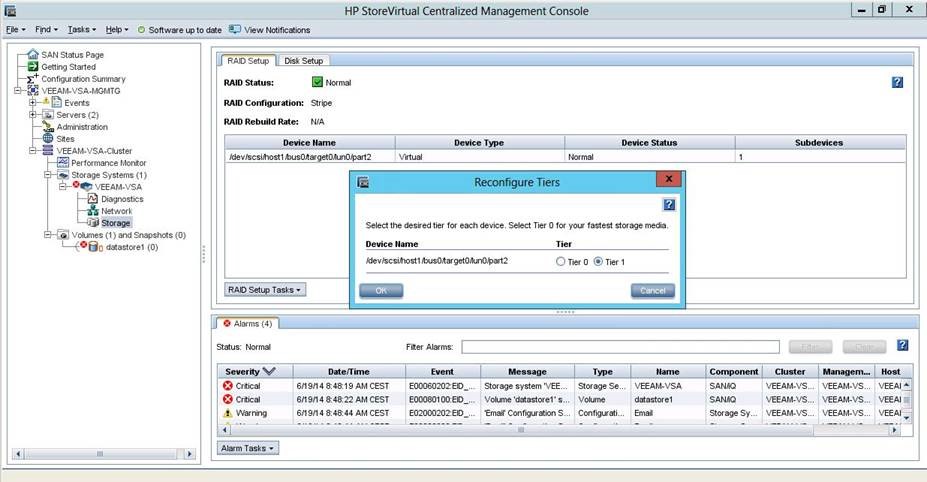
Use new Veeam Storage Snapshot Feature (HPE StoreVirtual including VSA, HPE 3PAR StoreServ, NetApp ONTAP, EMC VNX(e), Cisco HyperFley) if you can (after Veeam v7 release) => Reduces Snapshot Lifetime to some seconds => No load and problems at commit because of less data. (This option can be counterproductive if you experience the 20 sec VSS timeout). Veeams Cisco HyperFlex integration avoid usage of VMware VM Snapshots at all.
h)
Use at minimum VMware vSphere 5.0 because of changes in the snapshot places and Background things. vSphere 6u1 lates patch level (Jan2016 upated) completely changed the way Snapshots are committed. I highly recommend to update to it if you have any problems round about Snapshot commit.
c)
To reduce Snapshot commit time (and to reduce data in the snapshot), try to avoid any changes at the backup time window (User, Background processes, Antivirus, ….). Also try to avoid that on all LUNs on the storage System itself (faster writes at snapshot commit).
d)
If you cannot avoid many changes on block level at your backup window, use (Forward) Incremental with or without synthetic fulls. Reverse Incremental will take a bit longer than the other backup methods as they perform 3x more IOs at backup target within the snapshot lifetime. This lead to longer snapshot lifetime and at the end the Snapshot removal process has to handle more data.
f)
To reduce backup time window and snapshot lifetime, use Direct SAN or Direct NFS Mode. If you can not use one of them, use NBD-Network mode for Exchange backups. Avoid in any way HotAdd processing with NFS Datastores (which are not supported by Exchange in any way either). Keep an eye on Proxies that run on AutoDetect transport mode if they use the correct mode!
Disable VDDK Logging for Direct SAN Mode if your backups themselves run stable (ask Veeam support for the registry key and consequences). This tip is important if you have more than 10 LUNs connected to the Veeam Proxy.
As well very important is that you install and configure the correct multipath driver for your storage on the Proxy. Run the storage with host profile VMware even if the Veeam Proxy is a Windows System. (In no way use Windows Failover Cluster host profile at the Host access setting on the storage system)
e)
To reduce Snapshot lifetime and reduce amount of data to snapshot commit, use new Veeam parallel processing with enough resources to backup all of your disks at the same time (after v7 release). => Potentially add more Proxy resources. This tip is somehow outdated, as parallel processing is now enabled by default.
g)
Use actual VMware Versions as the newest VMware VADP/Storage API version are then available and the SnapShot commit process will get latest optimizations.
Use actual Veeam Versions (newer VDDK integration).
Install latest patches/updates for VMware ESXi/vCenter and Veeam.
i)
Still problems: Use faster disks for all of the VM disks (do not forget to place the OS disks on fast storage !!!). It is very important to not place the OS disk on a datastore with hundreds of other OS boot disks.
Keep an eye on the Storage Latency. On average it should not be higher than 30ms for all disks (including OS) and maximum latency should not go above 40ms. Original latency numbers from Microsoft are 20ms and max. 50ms, but specifically the max latency should not go above 40ms BEFORE you perform a backup and process Snapshots.
http://blogs.technet.com/b/mspfe/archive/2012/01/24/how_2d00_to_2d00_troubleshoot_2d00_microsoft_2d00_exchange_2d00_server_2d00_latency_2d00_or_2d00_connection_2d00_issues.aspx
j)
Less VMware VM disks can help to reduce snapshot commit time. By default even with no delta change data each disk will slow down snapshot commit. This time was reduced by 4x with ESXi6U1Feb2016 patch level.
k)
In a worst case scenario and no other tips help, you can check the following VM setting. This an undocumented VMware VM setting and you have to check with VMware the support statement. This was a tip from one of my customers with 13TB+ Exchange environment, who had a long run with VMware Support.
snapshot.maxConsolidateTime = “1” (in seconds) (again do this only together with VMware support). This setting was used with ESXi 4 and I think at least for vSphere 6 it is not usable as the SnapShot process was changed.
l)
If you have problems with cluster failover at Backup, one option is to backup DAG member(s) that hold only inactive databases (no cluster failover because of no active databases). The Logfile Truncation will be replicated by Exchange in whole DAG in that case. This give you also the option to restart the server or services and Exchange process VSS consistency more faster afterwards. If you restart the services, take care that you wait long enough afterwards that also the VSS Exchange writers come up again, before you backup. I saw some customers restarting VSS framework and immediately had performed a successfull backup as no VSS writers where registered at that point in time.
If you add an additional DAG member server for this, you have to check with you Exchange Architect the failover planning, because you change the member count for quorum failover selection. (e.g. you have 2 Exchange DAG members on different datacenters and a whiteness disk on datacenter 3. You add an additional Exchange Server on one side, the failover is affected because of different server count at the one of the datacenters.)
If you do so please monitor the Logfile Truncation replication processes in windows ecent log. Check that Windows Logs\ MSExchangeRepl Event 2046 occurs (Backup is happening for Database XXX) and there will be as well other messages that state that replication of log truncation happened. If you perform backup of an active Database there are other log messages for replication:
Applications and Services Logs \ Microsoft \ Exchange HighAvailability \ TruncationDebug
• Event 224 – The replication service decides which logs to truncate
• Event 225 – No logs will be truncated (either not enough logs or Circular Logging is enabled )
• Event 299 – The replication service truncates the logs ( or will tell you that there is no minimum amount of logs for truncation)
ap)
Not all Logfiles are deleted in a DAG at successfull Logfile Runctaion.
Please read: https://blogs.technet.microsoft.com/timmcmic/2012/03/12/exchange-2010-log-truncation-and-checkpoint-at-log-creation-in-a-database-availability-group/
v)
Install MS recommended fixes to avoid cluster failover problems.
Keep in mind that there are hotfixes that are recommended from Microsoft, but they are sometimes not in Windows update included!!!
Windows 2008 R2 http://blogs.technet.com/b/exchange/archive/2011/11/20/recommended-windows-hotfix-for-database-availability-groups-running-windows-server-2008-r2.aspx
Windows 2012
http://support.microsoft.com/kb/2784261 http://social.technet.microsoft.com/wiki/contents/articles/15577.list-of-failover-cluster-hotfixes-for-windows-server-2012.aspx
Windows 2012 R2
http://support.microsoft.com/kb/2920151
y)
Delete all existing VM Snapshots before you start. Existing SnapShot can slow I/O at Storage processes like Snapshot commit. As well existing snapshots will make it impossible to enable VMware Change Block Tracking. This could lead into 100% data read at any backup(Snap and Scan Backup), which cause longer Snapshot lifetimes with longer snapShot commit phases.
aa)
Maybe not directly related but some of the customer reported that they had high CPU/RAM usage and where able to fix logfile truncation problems by adding more CPU/RAM resources to the VM.
ab)
Use newest avilable VMware Tools version within the VMs. This is NOT optional.
Tips for preventing VSS (timeout) problems:
Cause:
If you perform an VSS based consistency on an exchange server, hard coded 20 second timeout release the Exchange VSS writer state automatically if the consistency state are hold longer than these 20 seconds. The result is that you cannot perform consistent backups.
In detail, you have to perform Exchange VSS Writer consistency, VM snapshot and Exchange VSS writer release in these from Microsoft hard coded 20 seconds.
With newer Veeam Backup & Replication versions, Veeam will detect this automatically and perform another kind of VSS snapshot to avoid this completely. See tip x)
So if you have another backup application and run into the timeout:
m)
If you see Exchange VSS Timeout EventLog 1296 => Change Log setting =>
Set-StorageGroup -Identity “<yourstoragegroup>” -CircularLoggingEnabled $false
x)
Use at least Veeam Backup & Replication v8. If standard VSS processing of a Microsoft Exchange Server times out, the job will retry processing using persistent in-guest VSS snapshot, which should prevent VSS processing timeouts commonly observed with Microsoft Exchange 2010. Persistent snapshots are removed from the production VMs once backups are finished. All VM, file-level and item-level restore options have been enhanced to detect and properly handle restores from Exchange backups created with the help of persistent VSS snapshots.
n)
In many cases Exchange can perform consistency more faster if you add more CPU/Memory to the VM. Based on customer feedback this solved many of the VSS timeout problems.
o)
Use faster disks for all of the VM disks (do not forget to place the OS disks on fast storage as well !!!)
The worst thing you can do is to place the OS disk on a datastore with hundreds of other boot vmdk volumes on a Raid5/Raid6 storage.
p)
Use at minimum VMware vSphere 5.0 because of changes in the snapshot creation area.
q)
Use actual VMware Versions (newest VADP/VDDK Kits with a lot of updates in it) and actual Veeam Versions (newer VDDK Integration). And install actual ESXi/vCenter patches! => to perform snapshot processing faster
r)
Important one on VMware side: Less VM disks will reduce snapshot creation time. Check how long it take to start a snapshot of the VM in VMware vSphere (web) client. Think about that you need to perform Exchange VSS writer consistency + VM snapshot in 20 seconds.
s)
To optimize snapshot creation time:
Check your vcenter load and optimize it (or use direct ESX(i) Connections for Veeam VM selection, so that the snapshot creation took less time.)
t)
Check your health an configuration of Exchange itself. I saw some installations where different problems ended up with a high cpu utilization at indexing service. This prevented VSS to work correct. Check also all other mail transport-cache settings. Sometimes the Transport Service cache, replicate shadows of the mails over and over again and nobody commit them. This is typcially the case if firewalls are not set up correctly. Sometimes only SMTP is allowed but not the Transport Service windows service interaction.
u)
Veeam specific: Veeam performs VSS processing over the network. Check with Veeam UserGuide TCP Port Matrix that B&R Server can perform Veeam Guest Processing over the network (open Firewall Ports).
If this is not possible Veeam failback (after a timeout) to network-less VMware Tools VIX communication channel (Veeam own) In-Guest processing. If you use network-less In-Guest processing, change the veeam registry key, so that VIX based processing is performed before network In Guest processing. => No wasted time because of waiting for timeout.
However network based In Guest processing is performed faster and I recommend it.
w)
One of the Forum member report VSS problems when a PublicFolder database is present on the server. If the above mentioned tips did not help, temporarily disable your PublicFolder DB or replicate (DAG) it to another server. If the backup then runs fine, check with your Exchange Architect the PublicFolder DB configuration. Another option can be to upgrade to Exchange 2013 because no special PublicFolder DB needed (PublicFolder are covered by normal mailbox DBs).
z)
Delete all existing VM Snapshots before you start. Existing SnapShot can slow down SnapShot processing.
aq)
If you face WMI error 0x80041032 after Windows Update / Host Update, change ArbTaskMaxIdle was set to 3600000 as described here https://support.microsoft.com/en-us/help/4096063/new-wmi-arbitrator-behavior-in-windows-server-2016-and-2012-r2 and reboot the host. If this do not help, contact Microsoft Support.
Tips for restore planning with Veeam:
ac)
It doesn´t matter if the VM that you had backed up holds active or inactive DAG enabled databases for Veeam Explorer for Exchange based restore. Enable InGuest processing of Veeam so that Veeam can interact with the OS and Exchange to bring it into a consistent state. As well it allows Veeam to set some restore awareness settings, so that the OS and Exchange detect/knows when a restore is performed.
– Instant VM Recovery/VM Restore/QuickRollback. OS will boot and because of the restore awareness settings Exchange will perform automatic recovery steps at the DB. You can find this step documented in the Event Log. Depending of the Exchange Version it can have another EventID. For Example Event ID 9618; Event Source MSExchangeIS; General Exchange VSS Writer (instance GUID) has processed post-restore events successfully.
To enable this automatic step, you need to boot the VM at restore with network.
– Veeam Explorer for Exchange based Single Iteam (Mail/Calendar/…) Restore is as well compatible with inactive and active Databases.
ad)
Veeams Explorer for Exchange will be started within the Veeam console if you want to restore a single item like mails, calendar entries,… . It will load the actual ese.dll from the Exchange Backup and access the Exchange Database Files directly out of the backup. This way Veeam is automatically compatible with all Exchange Updates and fixes even if there are changes within the DB structure (ese.dll abstract this to Veeam).
With this process you have to think about 2 things at the design:
– ese.dll can load (by the way Veeam uses the dll) “only” 64 databases. database number 65 will not be loaded. But you can unload one or more of the other 64 database and add the others manually.
– Veeam need a specific time per database for the mounting. The time depends on the backup target storage that you use. For example if it will take 10 seconds per database, it will take 1 Minute to mount 6 databases, but it will take 10 minutes to mount 60 databases. So a kind of best practices is to keep the database count at a reasonable level. A workaround can be to start the Win File Level Recovery and to start the Veeam Explorer for Exchange from there and select only the needed databases manually to shorten up the restore process.
ae)
If you “only” have a crash consistent backup or snapshot, you can use the Veeam Explorer for Exchange as well. Start the Veeam Win File Level Recovery Wizard and from there the Veeam Explorer for Exchange. As Veeam didn´t had the chance to collect the database places at backup (crash consistent) you can add each database and it´s logfile manually.
af)
Veeam support single object restore of Public Folders as well. Depending on the version and settings you maybe have to export data to a pst file with the Veeam Explorer for Exchange wizard if you can not send the data back to the public folder database/mailbox. The PST data can be mounted to a Outlook and you can copy and paste back the data if needed. If you face an empty Public Folder with Veeam Explorer for Exchange, please contact Veeam support there is a hotfix available.
ag)
If you want to use Export to PST, Veeam needs an Outlook 64bit on the server/workstation which run the Veeam Explorer for Exchange.
ah)
PST Explort places a documentation in the root of the pst that is compatible with the demand of court and lawyers. A restore protocoll which document all restores can be found at the Veeam UI at the “History-Restore” part.
ai)
If you are not allowed to access mails directly at restore, you can use the Veeam Enterprise Manager and it´s iteam restore possibilities to restore only changed/deleted files from a specified time period (without to get access or see the mails themself). This is for example sometime needed to be inline with the law and employee council (Betriebsrat).
aj)
Veeam Explorer for Exchange uses Exchange Web Services (EWS) for restore. Please check that EWS is working correctly and the Veeam Explorer can acess a CAS Server by TCP 443. DNS is in most cases needed. As the Explorer write directly into the mailbox of the user, the at restore defined user needs to have write access to the mailbox. You can define the restore user that write to the mailbox at restore. It can be the original user, and admin user or a user that you give temporary access to the mailbox for restore.
ak)
Veeam do not use any recovery database processes. So you can save this space on the Exchange Server. As these process isn´t used for any restore you save a lot of time at restore as well and reduce complexity dramatically. On the other hand Veeam can not restore a single database compleatly with the wizard. You have to create a new database with the user mailboxes and let the Veeam Explorer for Exchange restore the mailbox data. This protects you from any database corruption that is maybe within the backup but is not detected when you do a legacy restore of the database. However if you want to perform a database restore, you can use the Veeam file restore wizard to restore all needed database and logfiles and perform the other needed steps manually according to the Microsoft recovery steps: https://technet.microsoft.com/en-us/library/dd876954(v=exchg.150).aspx There are as well a lot of more illustrated recovery examples available at the internet. Just google for them.
al)
For Veeam restore it doesn´t matter if you have one DB by vmdk or multiple. If you place the Exchange Server on VMware, you shold keep the VM disk count low to streamline snapshot commit processes that are used at backup (see above). In most cases you should keep the count below 8-10 and use ESXi6 U1 with Feb 2016 patch level that reduces overhead at snapshot commit dramatically.
am)
The data amount per DB do not matter for Veeam, beside the data amount that you have selected for restore. The mount of the database at Veeam Explorer for Exchange is not really affected by the database size.
ar) If you force Kerberos only authentication (disable NTLM) make sure to add the Veeam Guest Interaction Proxy (potentially the Backup Server) to the Domain. THis is a requirement of Kerberos only authentication as it works only within Domains. Potentially you will run into the following 2 errors: “Unable to perform application-aware processing because connection to the guest could not be established” and “Unable to process Microsoft Exchange transaction logs because connection to the guest could not be established”. If this is the case in combination with Kerberos only authentication policy, then follow the following Microsoft guidelines: https://docs.microsoft.com/en-us/windows-server/security/kerberos/configuring-kerberos-over-ip
and use gpupdate /force or reboots of all affected systems.
5. More Veeam specific Exchange Tips and Tricks for transport role backups
Shadow redundancy can help to protect your undelivered messages by replicating them immediately to a second transport role. Even this is more important with Exchange 2013 because DAG members are transport role servers as well.
Check with your Exchange Architect, that you backup at least one Transport server that holds an original or a shadow of your undelivered mails.
If you backup only one Exchange 2013 DAG member that holds only offline databases (or Exchange 2010 DAG members that has transport role enabled), check the requirements section of this article to analyse if you backup everything what you need.
http://technet.microsoft.com/en-us/library/dd351027(v=exchg.150).aspx.
You also need to check that your backup software works application aware (e.g. Veeam Guest processing) and that in case of a restore the transport role detect the restore scenario as well and do not deliver already sent messages a second time. This is done by VSS processing at restore. VMware Tools quiescence at backup cannot achieve this by design.
A common configuration is to use a full blown Exchange Transport Role Server, instead of an Exchange Edge as an SMTP Gateway to the internet. In many cases, this is done to save some public IP addresses for running CAS Server on the internet on the same server.
You will likely place this Server in your DMZ and open only needed port 25 for mail transfer. This isn´t enough if you have enabled shadow redundancy because the shadows are not being committed anymore. Disabling shadow redundancy only because of this isn´t acceptable as they potentially lead to some lost mails if you lose one of the transport servers. Think about you lose one Server with and mail that has “the opportunity of your (your companies) life” mail in it.
Backup of IP Less DAG with Exchange 2013 SP1:
There is an cluster operation mode for exchange mailbox role where you do not need any Cluster IP address and name. You need to check if your backup software can handle this. Veeam Backup & Replication uses the VSS Exchange writer to bring the Information Store in a consistent state. No change needed for IP Less DAG. The restore is done by EWS and as well not affected. Good news for Veeam users.
6. More Veeam specific Exchange Tips and Tricks for CAS role backups.
You had 2 options with Exchange 2010 to achieve CAS redundancy.
1) External Layer 7 load balancer
Two or more CAS Server are placed behind an (redundant) load balancer that hold a cluster IP address. The Load balancer is aware if your CAS Server answers on a service port and how long the answer time is. This is the recommended way of doing CAS redundancy and no special things are needed for CAS backup.
2) Windows Network Load Balancing (NLB).
Windows is used to create a cluster IP address and all servers can answer to requests. Main problem here is that it is not service aware. So if your server is up and answering in the network but your Exchange CAS Service is down, your users do not get answers on a random base. => Invest in External Load Balancers!
If you want to try Windows NLB cluster way, you need to keep an eye on the configuration when using Veeam for backup. Veeam Guest Processing will read out VMware Tools IP address list and will use the first found IP address in the list and contact the VM. If the first IP address is the cluster address the guest processing might be connect to another server because NLB cluster route it to another VM.
So you can do one of the following:
1) As VMware Tools list IPs ascending, the NLB Cluster IP needs to be higher than the normal addresses.
2) If you cannot change the IP addresses (Public IPs for example) you can ask Veeam support for a hotfix that “Invert IP order guest processing Inverseipprder.zip”
3) Another option is to use VIX processing instead of direct network connection for Veeam Guest processing. The easiest way to do this is by blocking all communication to this VM over the network (Windows Firewall/your company firewall/…). Let port 443 open for Veeam explorer for Exchange restores.
In general you can get some background information about this here:
http://technet.microsoft.com/en-us/library/jj898588(v=exchg.150).aspx
Additional Tips:
7. Windows Storage Spaces are not supported within a VM
I saw lately 2 customers running Exchange databases on Storage Spaces within a VM. They did this because of 2TB Storage system limitation.
It is not supported based on a lately updated articel from Microsoft:
http://social.technet.microsoft.com/wiki/contents/articles/11382.storage-spaces-frequently-asked-questions-faq.aspx#What_types_of_drives_can_I_use_with_Storage_Spaces
” Storage layers that abstract the physical disks are not compatible with Storage Spaces. This includes VHDs and pass-through disks in a virtual machine, and storage subsystems that layer a RAID implementation on top of the physical disks. iSCSI and Fibre Channel controllers are not supported by Storage Spaces.”
Veeam specific:
Veeam Explorer for Exchange maps the VM volumes out of the backup to a windows system. Storage Spaces volumes are not imported automatically from windows, so the Veeam Explorer can not access the filesystem which hold the Exchange databases.
When you start a Veeam Window File Level Recovery Wizard for a VM that contains storage spaces volumes, you can see only System Volume Information folder on the drive.
Workaround if you really need mails from such a sceanrio:
Boot the VM with SureBackup in a Veeam “OnDemand” Virtual Lab. Stop the exchange service on the Virtual Lab Exchange Server and use Veeam Explorer for Exchange to access the databases for restore.
If there is no way to migrate the data to a single big volume or to spread the User Mailboxes accross individual small databases that fits the volume size needs, you can use Dynamic Disks to expand the drives. At least this is supported from Veeam side for Exchange restores. Based on Microsoft https://technet.microsoft.com/en-us/library/ee832792.aspx this is as well a supported way from Microsoft for Exchange. “Dynamic disk: A disk initialized for dynamic storage is called a dynamic disk. A dynamic disk contains dynamic volumes, such as simple volumes, spanned volumes, striped volumes, mirrored volumes, and RAID-5 volumes.”
8. Additional Tips:
Use the Veeam Forums http://forums.veeam.com and search for specific Exchange Topics, there you can find additional tips and feedback. Keep in mind that Veeam Forum is not a official support forum. If you need urgent help, please open a support ticket http://www.veeam.com/support . Testing and Proof of concept environments have support with lower priority.
9. Full Mailbox restore examples:
Depending on the usecase you have the following options:
Option 1) Repair the database from the other DAG copies: https://social.technet.microsoft.com/Fo … errecovery
Option 2) Use Instant VM Recovery or Full VM restore to recover the whole server
Option 3a) Create a new mailbox database and create the user. User standard Microsoft documented way to recover the user data: https://docs.microsoft.com/en-us/exchan … erver-2019
Instant VM Recovery to a new name (without boot) and remounting the disk can potentially help to make the process much faster as you do not have to wait until the data was restored to the recovery database (and you do not need extra space).
Option 3b) Perform the same with the Veeam explorer.
Create the new database and user mailboxes and user our Explorer for restore. It is the same approach as the Microsoft described way would be (Create database and mailboxes than recover data.
Option 4) DB file recover
– Recover the database and logfiles from Veeam to an empty folder or different folders.
Instant VM Recovery to a new name (without boot) and remounting the disk can potentially help to make the process much faster as you do not have to wait until the data was restored to the recovery database (and you do not need extra space).
– Check if the database files are clean shutown state with
If it isn´t run
(see as well https://blogs.technet.microsoft.com/msp … -recovery/)
– Creat the new mailbox database on the location where you want the database to run later:
New-MailboxDatabase -Name <yournewdatabasename> -Server <ExchangeServerName> -EdbFilePath <DatabaseFilewithpath> -LogFolderPath <LogFilesFolderPath>
– Mark the database that it can be overwriten
Set-MailboxDatabase <yournewdatabasename> -AllowFileRestore:$true
– Migrate the database files from the temporary location to the new DB location (rename .edb file if needed). Overwrite the newly created database. Wait until the data transfer finishes completely.
– Mount the database
mount-database <yournewdatabasename>
– Update the configuration like this (double check with the Exchange Administrators that it perform the right steps for the situation)
Get-Mailbox -Database <OriginalDatabaseName> |where {$_.ObjectClass -NotMatch ‘(SystemAttendantMailbox|ExOleDbSystemMailbox)’}| Move-Mailbox -ConfigurationOnly -TargetDatabase <yournewdatabasename>
Documentation can be found here: https://docs.microsoft.com/en-us/previo … =exchg.80)
– Redeliver the messages in the email queue:
uename> | Retry-Queue -Resubmit $true.
– Wait some time until AD Replication finish to replicate the changes and you can access the mailboxes again.
10. Additional Planning for Windows 2019
When Windows 2019 is used as base for Exchange workloads, you need to take some careful planning on the Veeam restore side. The Exchange iteam and File level recovery works in a way that you mount the Windows disk volumes at the Veeam Console and Mount Servers. If you use a Windows 2019 feature (for example ReFS) that has a newer version than the one on older Windows versions, you can not access the data for restore. Make sure to install a Veeam Console on a Windows 2019 Server and use as well a Mount Server (Repository configuration wizard) on such a windows version to avoid issues.
================
Do you have feedback?
Was one of the tips helpful?
Please leave a comment.
All the best to you and success… Andy

{kind=link}